DeepSeek公布全新论文,梁文锋署名
扫一扫
分享文章到微信

扫一扫
关注豌豆财经网微信公众号
1月13日消息,DeepSeek最新公布题为《Conditional Memory via Scalable Lookup:A New Axis of Sparsity for Large Language Models》全新论文,提出“条件记忆”(Conditional Memory)作为对主流条件计算(MoE)范式的互补性稀疏维度,旨在解决通过动态计算模拟知识检索的低效问题。

该论文作者署名包括梁文锋等DeepSeek团队成员,还有北京大学王选所赵东岩、张辉帅团队。
论文链接:https://github.com/deepseek-ai/Engram/blob/main/Engram_paper.pdf
提出“U形扩展定律”
论文称,当前大语言模型主要依靠混合专家(MoE)实现条件计算,通过稀疏激活参数扩展模型容量。然而,语言信号具有内在异质性:一方面需要深度动态计算进行组合推理,另一方面存在大量局部、静态、高度模式化的文本(如命名实体、公式化表达)。传统Transformer缺乏原生知识查找原语,迫使模型通过计算模拟检索,例如解析一个多词实体需消耗多个底层注意力与前馈网络层,本质上是昂贵地运行时重建静态查找表,浪费了本可用于高层推理的序列深度。
为匹配语言的双重特性,研究团队主张引入条件记忆(Conditional Memory)这一互补稀疏轴:条件计算稀疏激活参数以处理动态逻辑,条件记忆则依赖稀疏查找操作检索静态嵌入以获取固定知识。
同时,论文给出了该条件记忆具体实现方案Engram模块。
为量化Engram与MoE之间的协同,论文提出稀疏性分配问题。这也是该论文的核心。
团队设计了一个严格的实验框架:固定总参数量和每token的激活参数量(也就是计算量),然后在MoE专家和Engram记忆之间重新分配“闲置参数”预算。
实验表明,纯MoE或纯Engram主导均非最优,二者存在结构互补性:
MoE主导缺乏静态模式的专用内存,迫使通过深度计算低效重建。
Engram主导则失去条件记忆能力,损害需要动态上下文推理的任务。
最终,实验揭示了一条“U形扩展定律”(如下图):在固定参数与FLOPs下,将稀疏参数预算的约20%-25%重新分配给Engram可获得最佳性能。例如在10B参数规模下,验证损失从1.7248降至1.7109。
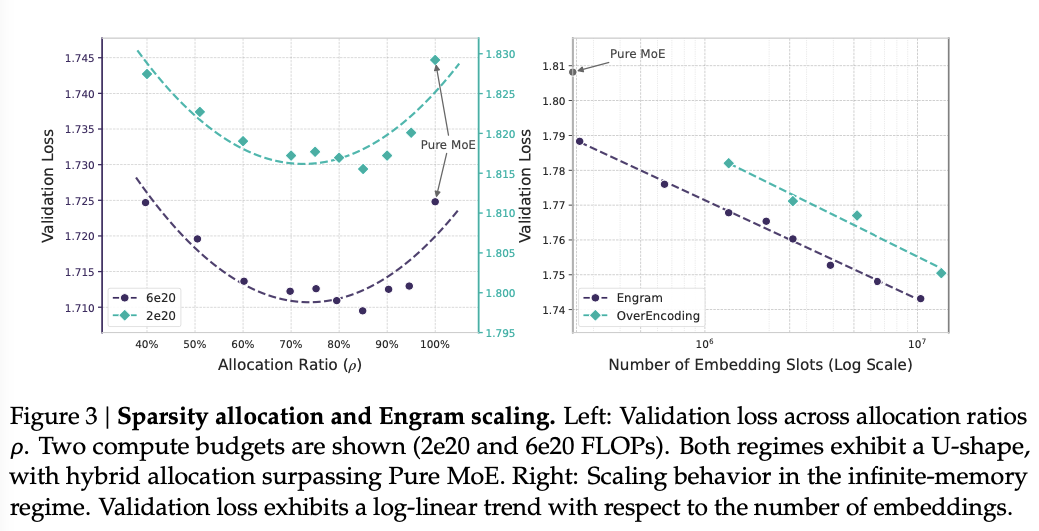
基于上述分配定律,论文团队训练了Engram-27B模型(总参数26.7B,激活参数3.8B),通过将MoE-27B的专家数从72减至55,并将释放的参数重新分配给5.7B参数的Engram内存(分配比ρ=74.3%)。在预训练后,相比同参数同FLOPs的MoE-27B基线,Engram-27B在知识与推理、通用推理、代码与数学等多个领域均取得显著提升。
具体提升包括:
知识与推理:MMLU +3.0,CMMLU +4.0,MMLU-Pro +1.8。
通用推理:BBH +5.0,ARC-Challenge +3.7,DROP +3.3。
代码与数学:HumanEval +3.0,GSM8K +2.2,MATH +2.4。
论文总结认为,Engram不仅提升知识检索能力,更在通用推理、代码与数学领域带来更大增益。机制上,它通过减轻早期层静态重建任务有效“加深”网络,并释放注意力容量以聚焦全局上下文与复杂推理,从而显著增强长上下文能力。其确定性寻址支持存储与计算解耦,为下一代稀疏模型提供了基础设施感知的高效设计范式。
DeepSeek-V4大模型被曝春节前后发布
值得注意的是,论文结尾明确提到:我们将条件记忆视为下一代稀疏模型不可或缺的建模原语。
就在前天,有外媒报道,DeepSeek将于2月发布新一代旗舰AI模型DeepSeek V4,该模型主打强劲的代码生成能力,是DeepSeek继2024年12月发布的V3模型之后的最新版本。
报道援引知情人士消息称,DeepSeek员工基于公司内部基准开展的初步测试显示,该最新模型在代码生成领域的表现优于Anthropic、Claude、生成式预训练变换器系列(OpenAI GPT)等现有主流模型。DeepSeek计划在2025年春节前后发布V4版本。
因此,论文中的提到的“条件记忆”(Conditional Memory)被业内猜测将极大可能应用于DeepSeek-V4大模型中。
自2024年1月20日,DeepSeek发布R1模型,恰逢春节前夕,其卓越的表现引发了全球AI界的广泛关注以来,DeepSeek团队持续不断给业内带来惊喜,2025年下半年几乎月月有发布。
2025年末,DeepSeek还发布了题为《Manifold-Constrained Hyper-Connections》的研究论文,该技术成功解决了此前阻碍大模型规模扩展的核心瓶颈——训练稳定性问题。通过在超连接技术中引入数学上的“流形约束”,DeepSeek实现了27B模型训练中信号放大从近3000倍骤降至1.6倍的惊人效果。为大模型架构设计开辟了一条全新的技术路径。
2025年12月1日,DeepSeek发布了两款新模型:DeepSeek-V3.2和DeepSeek-V3.2-Speciale,并开源。DeepSeek-V3.2 达到了 GPT-5 的水平,DeepSeek-V3.2-Speciale在主流推理基准测试上的性能表现媲美Gemini-3.0-Pro。
2025年11月,DeepSeek在Hugging Face平台正式开源了DeepSeek-Math-V2模型,这是全球首个达到国际数学奥林匹克竞赛金牌水平的开源数学模型。该模型基于DeepSeek-V3.2-Exp-Base开发。
2025年10月,DeepSeek发布3B参数开源OCR模型,DeepSeek-OCR模型创新性地提出“上下文光学压缩”技术,将长文本转换为图像进行高效压缩处理,大幅降低大模型输入所需的Token数量,从而显著降低大模型处理长文档时的计算开销,该模型迅速在AI领域获得了广泛关注和讨论。
2025年9月,DeepSeek正式发布DeepSeek-V3.2-Exp模型,并宣布API调用价格大幅降低,输入百万Token价格降至2毛钱,输出价格直降75%,被业界称为“价格屠夫”再挥刀。
蓄力这么久,业内认为,DeepSeek-V4版本的推出预计将对当前的AI竞争格局产生重大影响,期待其进一步巩固DeepSeek在全球人工智能领域的领先地位。
投稿邮箱:lukejiwang@163.com 详情访问豌豆财经网:http://www.wdyxw.com.cn
 DeepSeek-OCR 2大模型开源,重塑文档AI的认知逻辑
DeepSeek-OCR 2大模型开源,重塑文档AI的认知逻辑
1月27日消息,深度求索(DeepSeek)团队发布了论文《DeepSeek-OCR 2: Visual Causal Flo
豌豆AI2026-01-27








 头条资讯
头条资讯











